Building PM Practice: Extracting Real Product Decisions from Lenny's Podcast Transcripts
January 29, 2026
development projectsA practical guide to building a PM practice platform using Laravel, AI for scenario extraction and grading, and real product decisions from industry leaders.
Over Christmas break, I started working on something I'd been thinking about for a while. Product managers don't have a good way to practice real PM work. Programmers work through LeetCode problems. Designers share portfolios on Dribbble. PMs? We just talk about frameworks in interviews and hope people believe us.
The concept was simple: give PMs real product scenarios, let them write what they'd do, grade their reasoning, let them share results. I worked through this with Claude - framing the product, figuring out positioning, refining what this actually needed to be. We built the scaffolding in Laravel: CRUD for scenarios, grading system, admin tools with Filament.
The Problem I Couldn't Solve
Then I hit three problems:
Where do you get authentic scenarios? I could write scenarios based on my own experience, but that's limited to Laravel consulting and nonprofit tech. Real PM work spans consumer apps, enterprise software, marketplace dynamics, B2B SaaS. I needed scenarios from actual product leaders, not just my narrow slice.
How do you grade product judgment? Programming problems have right answers. Product decisions don't. The "right" answer depends on context - company stage, market conditions, team capabilities, user needs. How do you build a rubric for something fundamentally subjective?
Would people actually write thoughtful responses? Multiple choice feels wrong. Real PM work isn't "A) User research, B) Build MVP, C) Talk to stakeholders." It's messy. You need to show your thinking. But would people write 200-word answers to open-ended questions, or would this just feel like homework?
I had the Laravel app running. But I didn't have the content or the grading approach figured out. So I shelved it.
The Dataset That Changed Everything
Two weeks later, Lenny Rachitsky open-sourced all 269 transcripts from his podcast on GitHub.
I'd been listening to Lenny's podcast for months. What makes it different from most product podcasts is he gets people to tell specific stories about actual decisions they made. Not advice. Not frameworks. Actual decisions:
- Brian Chesky explaining why he reorganized Airbnb from 10 divisions back to a functional model
- Bret Taylor walking through how he designed the Facebook Like button
- Julie Zhuo describing how Facebook navigated the shift from photos to news feed
These aren't hypotheticals. They're real decisions with known outcomes. And suddenly I had access to all 269 episodes as text files I could process.
All three problems solved:
✅ Content source? Extract decision moments from the transcripts
✅ Grading approach? Use AI to evaluate reasoning quality, then show what the expert actually did
✅ Engagement question? If the scenario is interesting enough (Facebook Like button, Google Maps), people will write thoughtful answers
Extracting Scenarios from Transcripts
I started with the Bret Taylor episode. Read through and marked every decision moment. His Google Maps origin story alone had 5-6 decision points:
- Build Google Local first instead of jumping straight to Maps
- Acquire Keyhole for satellite imagery
- Design the "pushpin" interaction model
- Integrate search, local business data, and satellite imagery into one product
Each decision needed three pieces:
- Context (2-4 paragraphs): Set up the situation without spoiling the decision
- Decision point (1 open-ended question): What would you do?
- Expert answer: What they decided + why + outcome + lesson
Working with Claude, we built a prompt using Sonnet 4.5 to extract these from transcripts. The extraction prompt asks the AI to:
- Identify decision points where the guest made a specific choice
- Extract 2-4 paragraphs of context before the decision
- Frame the decision as an open-ended question
- Pull out what they actually decided and why
- Capture the outcome and lesson learned
First pass on Bret Taylor: 15 scenarios extracted. After manual curation: 10 keepers. The AI is good at finding decision moments, but I still curate to ensure quality and variety.
Time per scenario: ~5 minutes to extract with Sonnet 4.5, ~10 minutes to polish and verify. About 2.5 hours per episode for 10 production-ready scenarios.
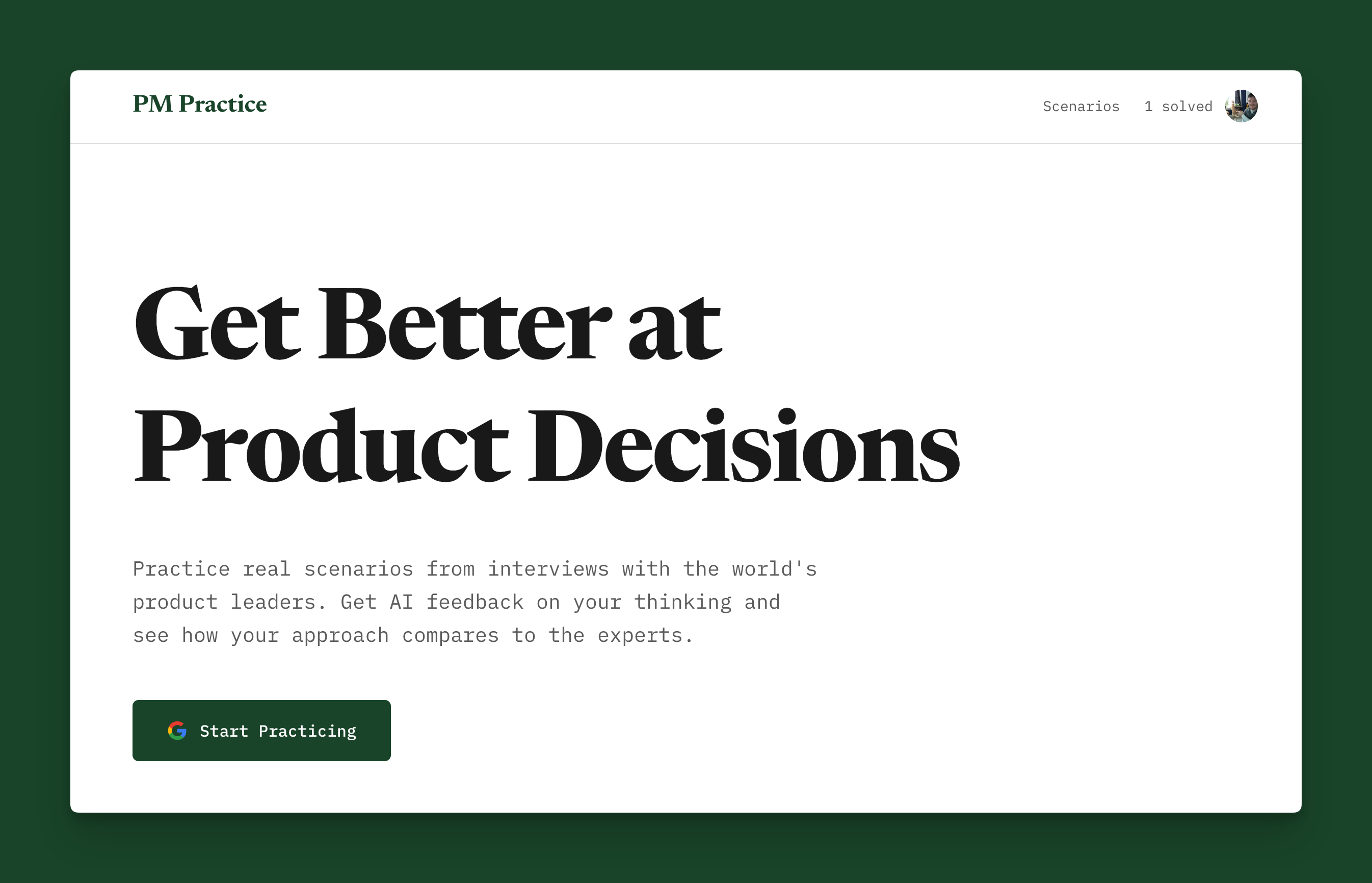
The Product Design
I wanted this to feel different from quiz platforms. No multiple choice. No gamification. No badges. Just clean, editorial design focused on thinking through the problem.
Design decisions:
- Typography: Newsreader for body text (readable, classic), IBM Plex Mono for UI elements
- Color: Forest green (#1a4d2e) - serious but not corporate
- Layout: Generous whitespace, focus on reading
- Aesthetic: Think NYT or The Atlantic, not Duolingo
User flow:
- Browse scenarios (filter by difficulty, category, leader)
- Read context (2-4 paragraphs, no spoilers about the decision)
- Answer the open-ended question (textarea, no character limit)
- Submit → AI grading
- See the expert answer (what they decided + outcome)
- Share results
Tech stack:
- Laravel 12 (my comfort zone)
- Tailwind 4, Alpine.js
- Filament 4 for admin
- Claude Sonnet 4.5 for scenario extraction
- PrismPHP wrapper → GPT-5-nano for grading
- Laravel Cloud for hosting
- MySQL 8
The Grading System
This was the trickiest part. I didn't want the AI to just check if your answer matches what the expert did. That would miss the point entirely.
The grading rubric (powered by GPT-5-nano) evaluates:
- Problem Understanding (20 points): Did you grasp the core challenge?
- Strategic Thinking (25 points): Did you consider multiple options and tradeoffs?
- Stakeholder Awareness (20 points): Did you think about users, team, business constraints?
- Execution Realism (20 points): Could you actually execute this plan?
- Communication (15 points): Can you explain your reasoning clearly?
Total: 100 points
The key insight: GPT-5-nano doesn't see the expert's answer when it grades. It only sees your response and the original context. This forces it to evaluate the quality of your thinking, not whether you happened to guess what Bret Taylor decided.
Implementation-wise, I'm using PrismPHP as a Laravel-friendly wrapper around various LLM APIs. Makes it dead simple to swap between providers or models. The grading happens asynchronously via Laravel queues - submit your answer, get graded in the background, see results when ready.
After grading, you see what the expert actually did and can compare approaches. Sometimes your answer is better than what they did. Sometimes it's worse. The point isn't to match their decision - it's to develop your reasoning muscles.
A Real Example
Here's what a scenario looks like in practice:
Scenario: The Facebook Like Button (Bret Taylor)
Context provides 2-3 paragraphs about Facebook in 2007, the challenge of reducing friction for user engagement, previous attempts at reactions, and the tension between simplicity and expressiveness.
The Question: You're leading the design of a new engagement feature. Do you build multiple reaction types (like, love, sad, angry) or keep it to a single action? What tradeoffs would you consider?
Your Answer: (User writes their reasoning - maybe 200-300 words)
AI Grades Your Thinking: Evaluates problem understanding, strategic tradeoffs, stakeholder awareness, execution realism.
The Expert's Decision: Bret explains they chose a single "Like" button for radical simplicity. Multiple reactions would create analysis paralysis and complicate the feed algorithm. The constraint forced clarity. They could always add more later (and they did, 9 years later with reactions).
You see immediately if your reasoning matched the level of thinking that led to one of the most impactful UI decisions in tech history. Even if you chose differently, you learn how world-class PMs think through tradeoffs.
What I Learned
Constraints force clarity. Couldn't figure out how to build this until Lenny open-sourced the transcripts. Having to wait for the right raw material forced clarity about what the product actually needed.
AI grading works better than expected. Was skeptical GPT-5-nano could evaluate product judgment. It's surprisingly good at assessing reasoning quality. Catches superficial thinking versus genuine tradeoff analysis.
Curation beats automation. Could auto-extract from every transcript. Would produce mediocre results. Better: Sonnet 4.5 extracts 15 candidates → I curate to 10 keepers → quality stays high.
What's Live
Right now: 10 scenarios from Bret Taylor
- Designing the Facebook Like button
- Building Google Maps from Google Local
- Creating FriendFeed's real-time feed
- Plus 7 more product decisions
Every Monday, subscribers get new scenarios from different product leaders:
- Brian Chesky (Airbnb org design)
- Julie Zhuo (Facebook design)
- Shreyas Doshi (product strategy)
- More coming
Goal: 50 scenarios by end of Q1, 100+ by end of year.
Try It & Connect
Want to practice product thinking with real scenarios from product leaders? Head to practice.pmprompt.com and try a few scenarios. It's free forever.
Building something similar with AI extraction and grading? I'm happy to share the prompt templates and discuss the technical approach. Find me on Twitter/X or email andy@pmprompt.com.
Special thanks to Lenny Rachitsky for open-sourcing the podcast transcripts. That dataset made this possible.
Resources
- PM Practice Platform - Live product
- PrismPHP - Laravel wrapper for LLM APIs
- Lenny's Podcast Transcripts - Open source dataset
- Laravel Cloud - Hosting platform
- Filament - Laravel admin panel